Lab 4: Distributed-memory programming
Generalities
-
Give the definition of network latency.
-
Give the definition of network bandwidth.
-
Give their respective units.
-
Give the name and version of the MPI library you are using. Give the command used to retrieve this information.
-
To make sure your installation works, you can use the hostname command, which returns the name of the current process’s host:
What happens when all processes are executed on the same host?Bash
Ping pong
Set up
In this exercise, you will do performance measurements using the ping-pong benchmark to familiarize with MPI’s characteristics communication times. Start by writing a ping-pong between two MPI processes. Rank 0 will send a message, and rank 1 will receive it. Write your code so that you can set the message size as a command-line argument.
-
The code hereafter is a simple ping from rank 0 to rank 1 (no answer). We have voluntarily added a
Using Open MPI 2.0.1, we measured the execution time as a function of message size. We obtain 53.1654 ms for a size of 4,000 Bytes, and 2.0006 s for a size of 4,096 Bytes. How do you explain this difference? What did we actually measure?sleep(2)in the rank 1′s code. -
Find the message size for which this gap appears in your MPI implementation. This size might be different than the one we observed using Open MPI 2.0.1 (4,096 B). Explain the reason why.
-
We decide to remove the call to
sleep(). Does the measure make sense now? Why? -
Propose an alternative to measure the actual sending time of a message (i.e. the time it took to actually receive it on the target rank). Write the corresponding program. It is strongly advised that you read the MPI documentation of the different modes of communications: Standard, Buffered, Ready, Synchronous, etc.
-
Write an actual MPI ping-pong (rank 1 answers back to rank 0). Explain why the measured times corresponds to a message exchange.
First measures
-
Do multiple measures with multiples of 32 Bytes for the message sizes. What do you see?
-
We propose adding a barrier before the message exchange phase. Explain what is the interest of this barrier with regards to the accuracy of the measurements.
-
Rerun the measures of question 11. Are the changes from the previous question sufficient? Why?
Repetitions
When taking a measurement, it is important to remember that our environment does not allow us to reproduce the exact conditions between each run. Moreover, time measurement itself is fraught with uncertainty. To solve this problem, we prefer to repeat measurements and calculate an average (mean, think about which one is the best) and a median. Alternatively, we can repeat runs until, e.g., the 95% confidence interval is within 5% of our reported means.
- Update the program to add repetitions. You should now print the average execution time.
Impact of message size
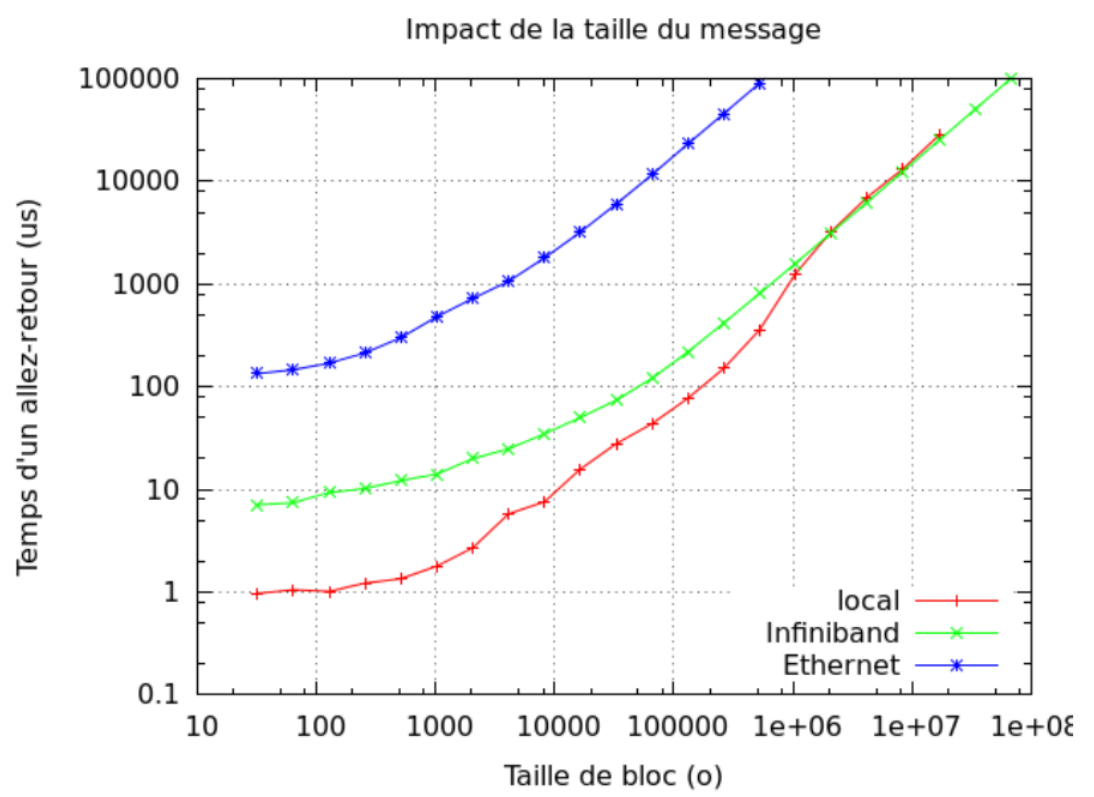
Fig. 1 shows the evolution of ping-pong time according to message size between intra-node (local) and inter-node (Ethernet and Infiniband) exchanges. Scales are logarithmic.
-
Explain why there is such a big gap between local and Infiniband for small sizes. Explain this gap shrinks progressively once the message size increases.
-
From the previous results, should we send distinct sets of data separately? Or should we try to group them together? Is it true for all sizes?
Collectives and algorithms in Open MPI
Using a recent version of Open MPI (5.x+), run the command ompi_info -all.
This gives you multiple informations about your installation.
We will use to know which algorithms are available in the coll tuned module of Open MPI, where blocking collectives are implemented.
-
Find what are the usable algorithms for the
MPI_Bcastroutine. Compare their performance depending on the number of MPI processes and buffer size. -
Find what are the usable algorithms for the
MPI_Gatherroutine. Compare their performance depending on the number of MPI processes and buffer size. -
Find what are the usable algorithms for the
MPI_Reduceroutine. Compare their performance depending on the number of MPI processes and buffer size. -
Find what are the usable algorithms for the
MPI_Alltoallroutine. Compare their performance depending on the number of MPI processes and buffer size. -
For each collective, why do we need multiple algorithms?
Experimental evaluation of scalability
Let’s start with a very simple benchmark. Our MPI program will initially make no communication. Have node 0 measure the program’s execution time. It will perform a simple sum of two vectors, in the following form:
with \(X\) a vector of size \(N\) and \(c\) a real constant.
Clearly, such an equation can be distributed over several MPI processes without any communication, so we will simply implement the sum method and execute it in a loop to obtain a suitable execution time for our measurement.
- Implement this benchmark like so:
- Initialize the MPI context
- Pass the vector size and the number of repetitions as parameters of the program
- Allocate and initialize memory for two vectors. Each node shall compute the sum on a vector of size \(\frac{N}{nb_{tasks}}\)
-
Make sure to measure the execution time as seen previously in this lab
-
What does strong scalability represent?
-
What does weak scalability represent?
-
To introduce communications in our program, we want to consider a case inspired by finite elements method (FEM). Our equation is now:
Here, MPI slicing requires the addition of communications for border elements. Modify the application in this way and evaluate scalability.
- Introduce a global synchronization in the repetitions loop and re-evaluate the application’s scalability. What do you see? What remarks can you make about communications and the use of barriers in MPI applications? What should you do to avoid this problem?